EDIT: With SiYuan >=3.0.0 setup is much easier. Please see my latest comment.
It is possible to serve a LLM locally using an OpenAI compatible API. It seems to be possible to use local inference with SiYuan:
Once
- Install ollama
- Install LiteLLM
pipx install 'litellm[proxy]'
ollama run orca2
Serve
ollama serve & litellm --model ollama/orca2
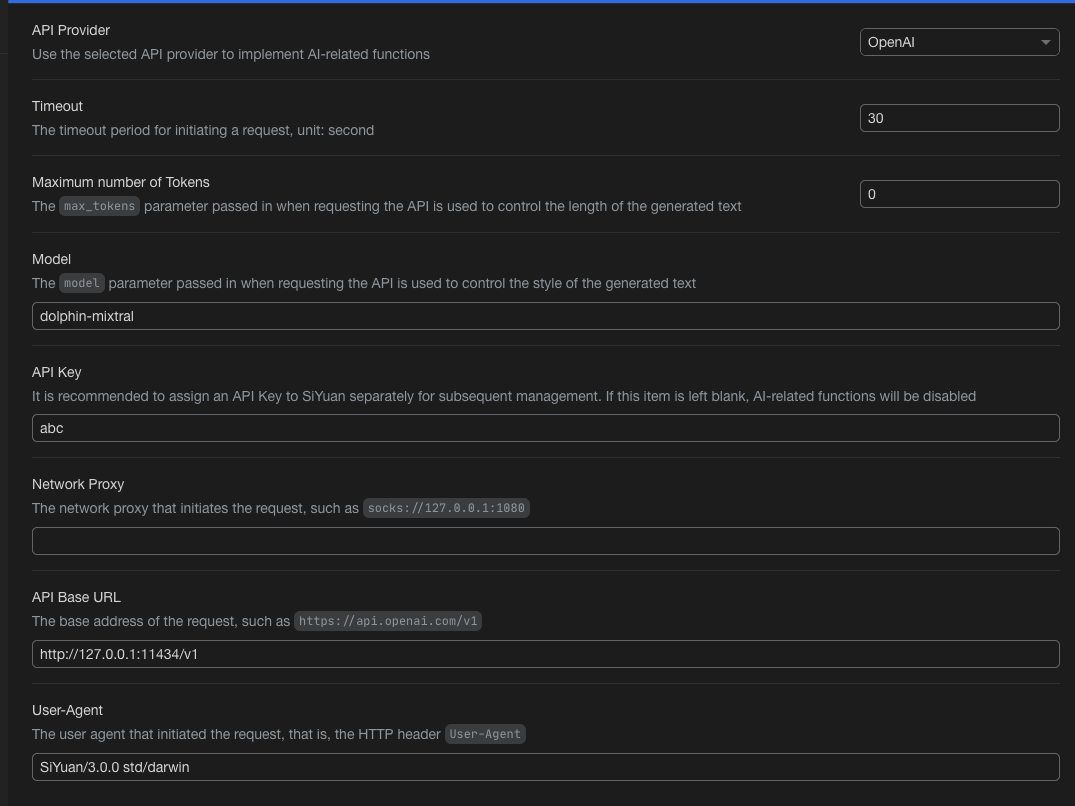
The settings in Siyuan are:
- Model: gpt-4
- API Base URL http://0.0.0.0:8000
I entered a dummy OpenAI API key (any value works)
You can use any model provided by ollama (or see liteLLM for even more models)
Welcome to here!
Here we can learn from each other how to use SiYuan, give feedback and suggestions, and build SiYuan together.
Signup About