Notebook Assistant (nb-assistant / 思源 笔记本助手) is a plugin that build for SiYuan to enhance its AI capability. It is now at 0.1.3 version, while this is a big release compare to 0.1.2, I'm writing a blog post to highlight its usage and changes.
This plugin is originally inspired by obsidian smart connections. I like SiYuan and I also want it to have something similar, and that's why it's built. As a Cloud Engineer, I'm dealing with tons of new technology and documentation to read every day, it will be good that there is a notebook for me keep all my notes and thoughts as well as my learning. Months later, when I checking out my old notes, it is getting more contents. I needs something to help with:
- Quick summary of my document
- Auto tagging the document for me to easier organize things
- Making use of my old note to create some contents.
- Search within my notes. (The current full text search on SiYuan is working great, I only need to find a similar contents while I forget about the keywords)
Notebook Assistant is focus on doing what mentioned above.
Setting up Notebook Assistant
In order to start using Notebook Assistant, you will need to configure AI setting under SiYuan. As a tool that aim to enhance its AI capability, I'm trying to rely on what is currently available. The screenshots below shows a setup for using llamafile (https://github.com/Mozilla-Ocho/llamafile).
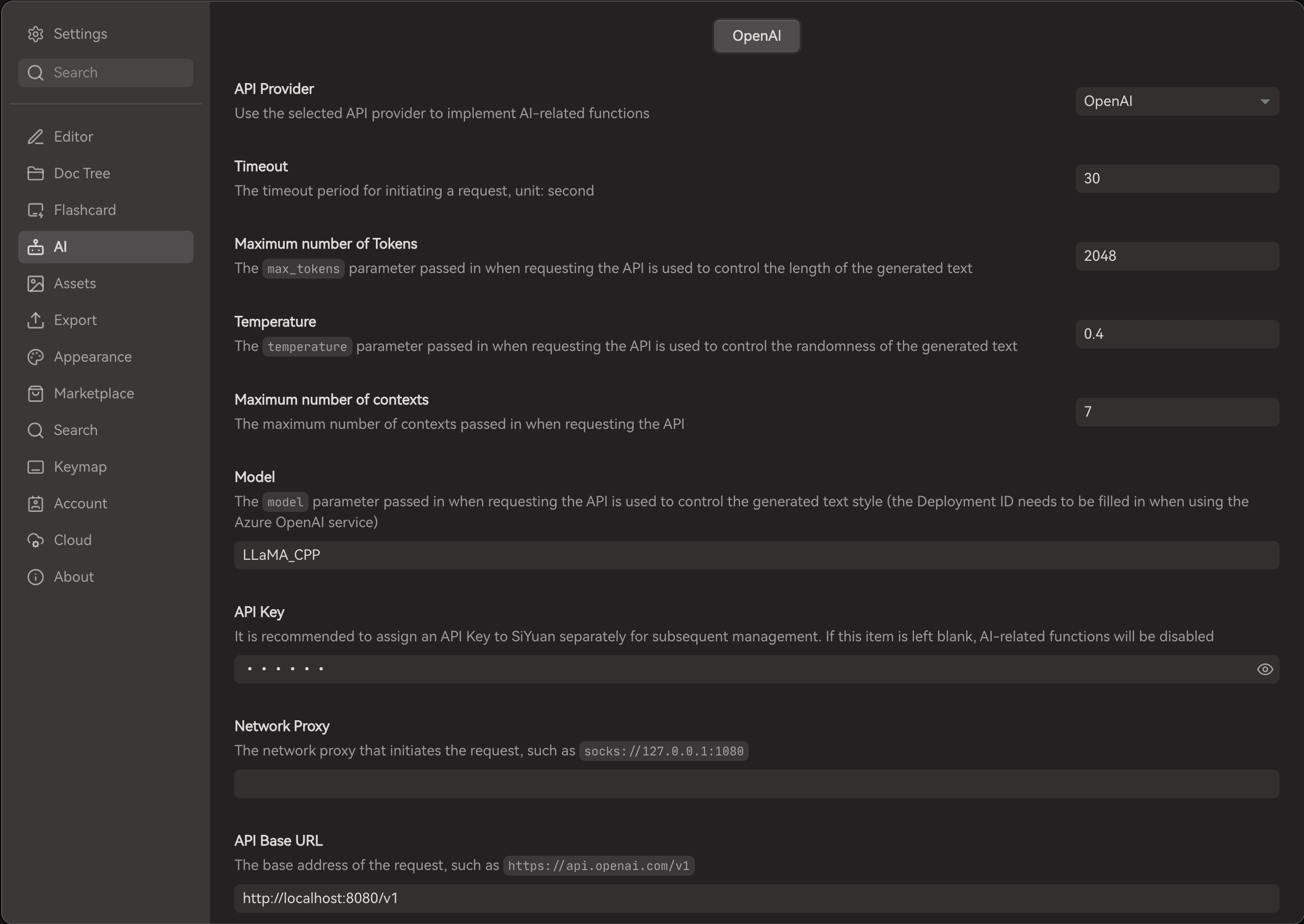
This plugin is developed by using deepseek ai as the AI backend. Results might be different when you are using different AI service provider. Do note that the current LLM still have hullucination in the information it generated.
Quick summary of my document
Summarize the document of my own. This function only allowing user to create summary from the opened document, once it is summarized, you can selected whether to appened to your document or copy it to somewhere else.
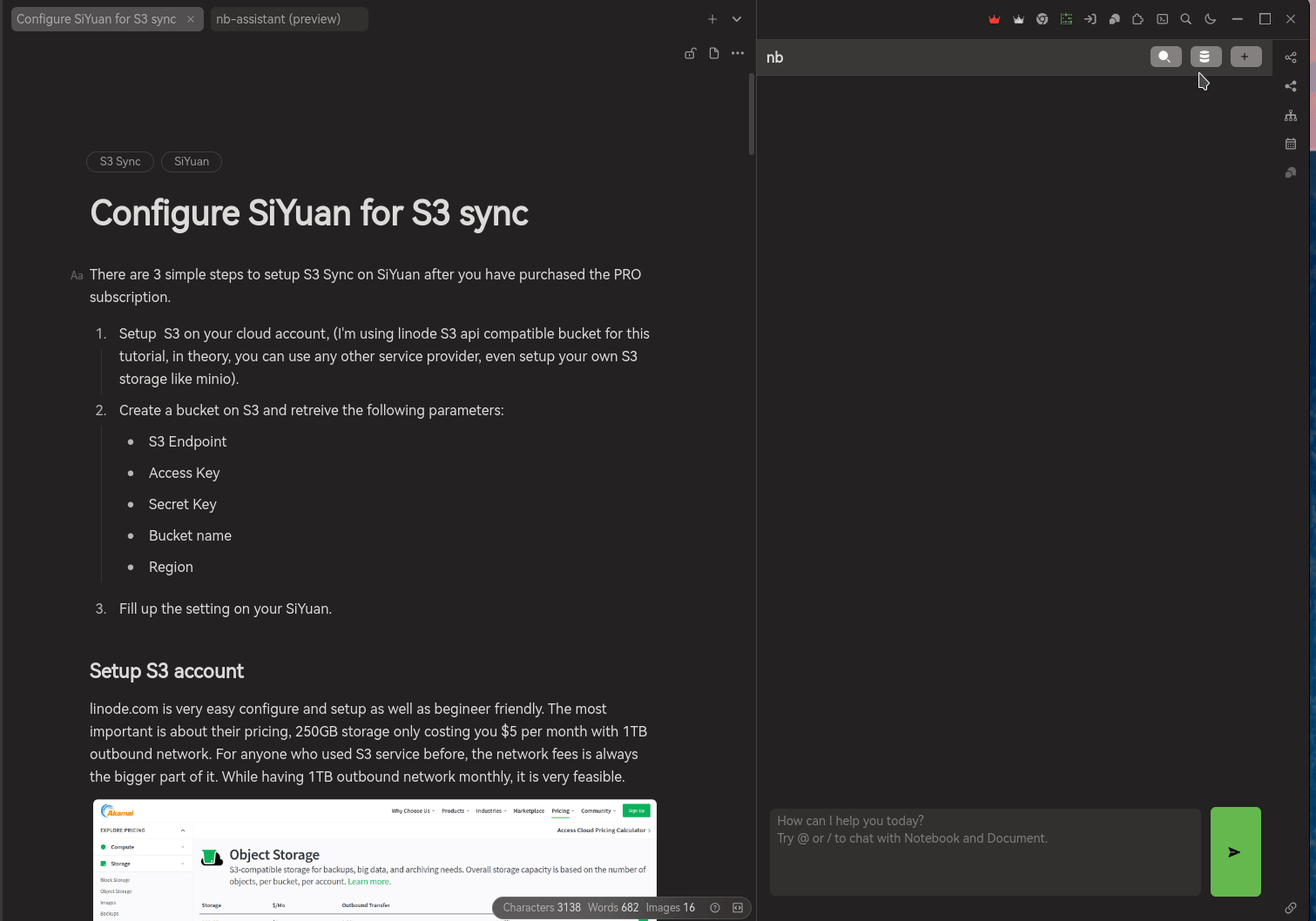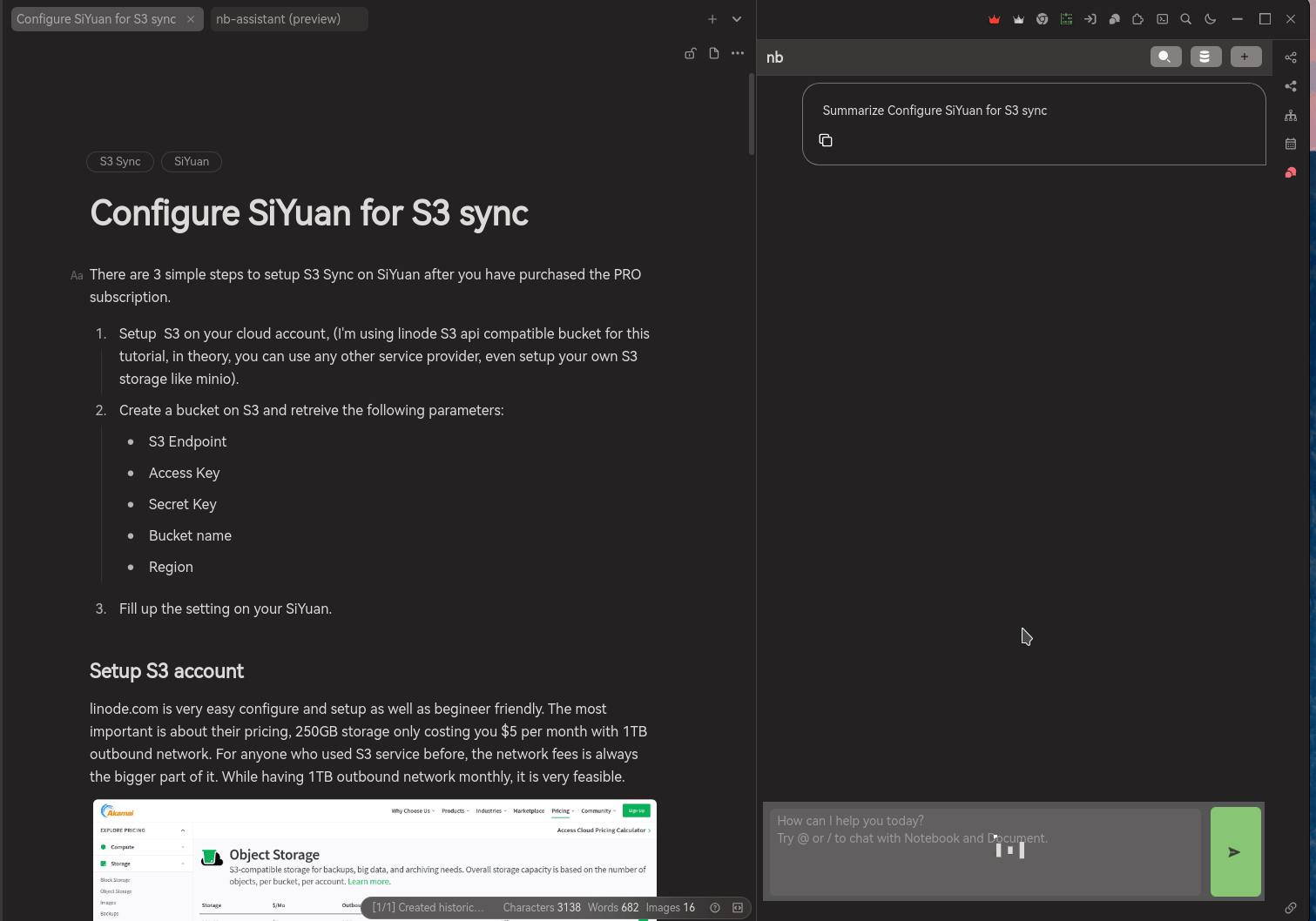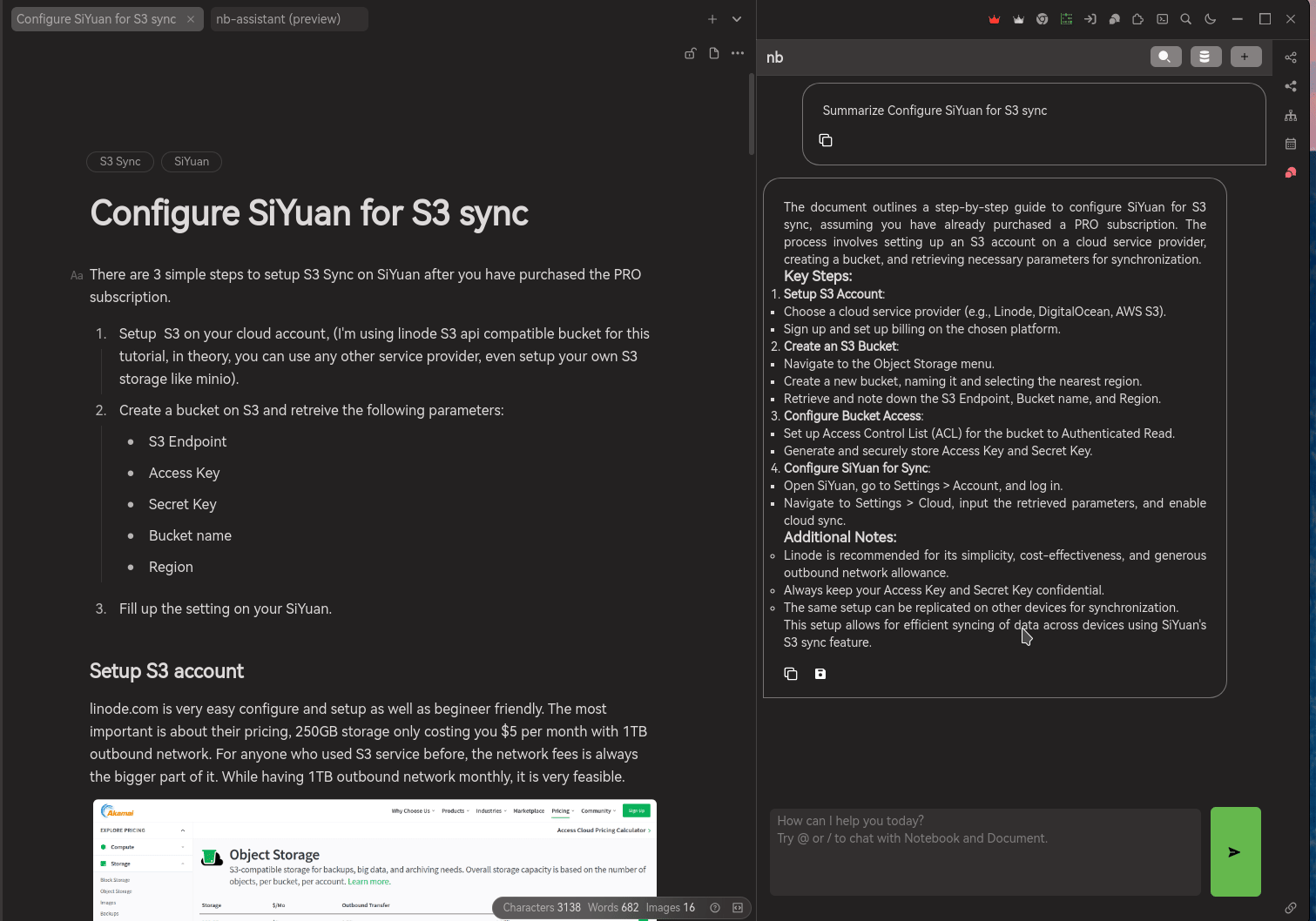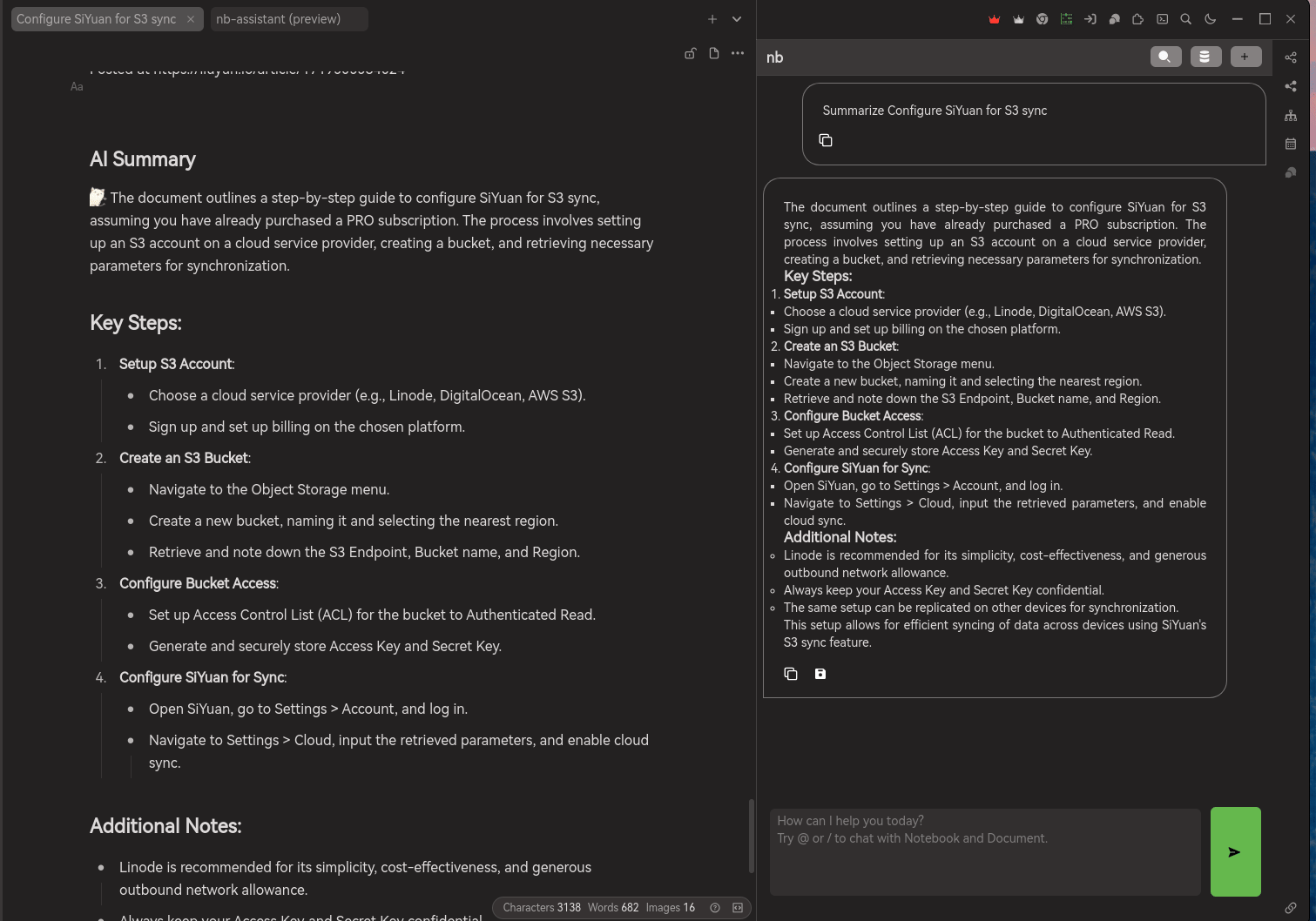
Also, for AI generated content, Notebook Assistant will be adding a hint in front of the text "AI Summary" and emoji to indicate that this is a content generated by AI. So, you will be aware of the truthless and trustworthy of the information.
Auto tagging the documents
I do not have the habit in tagging my document. Document with tagging actually more organize and easier to search. Letting the AI to help generate tags for the document and I'm able to select the related tags about it.
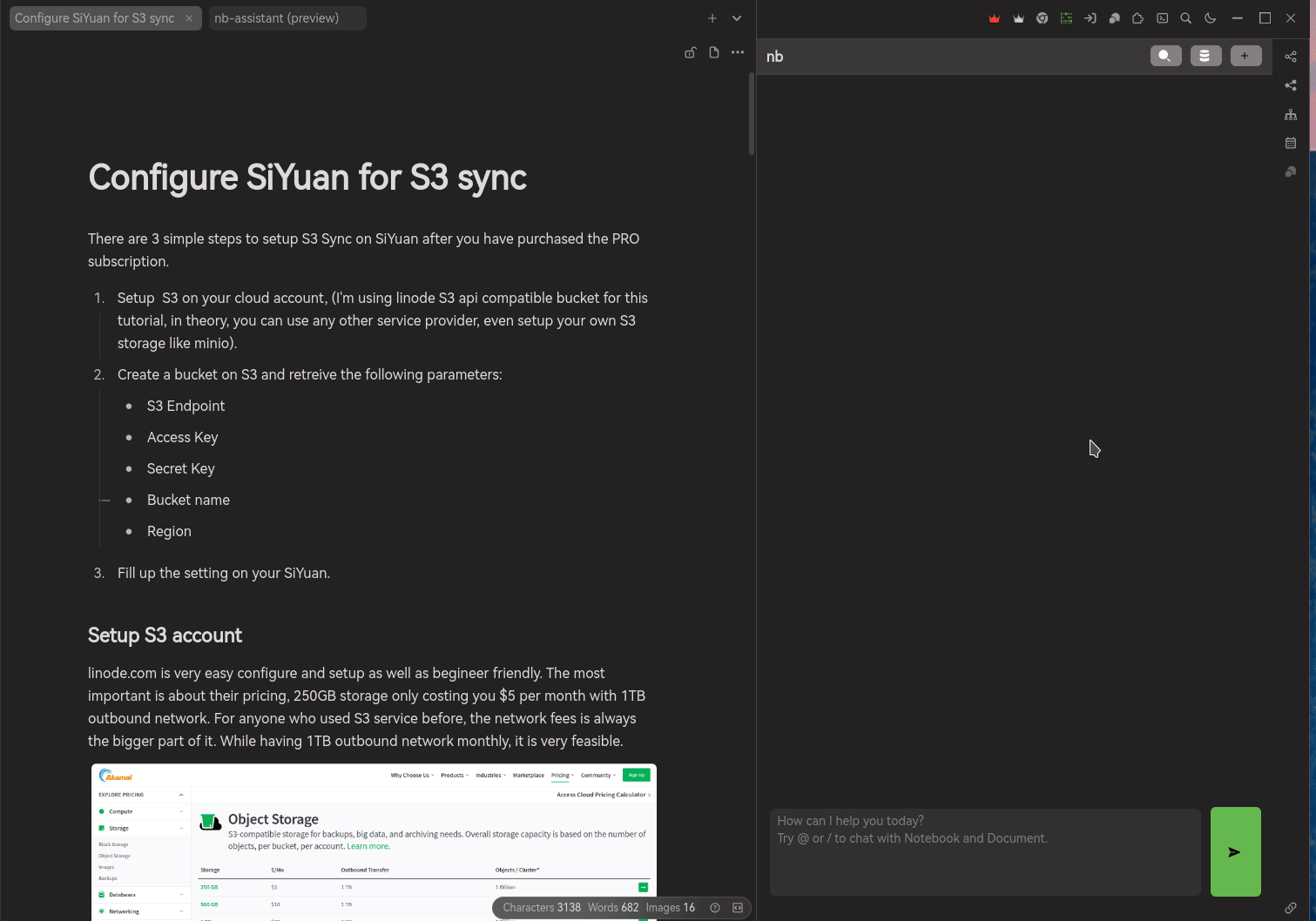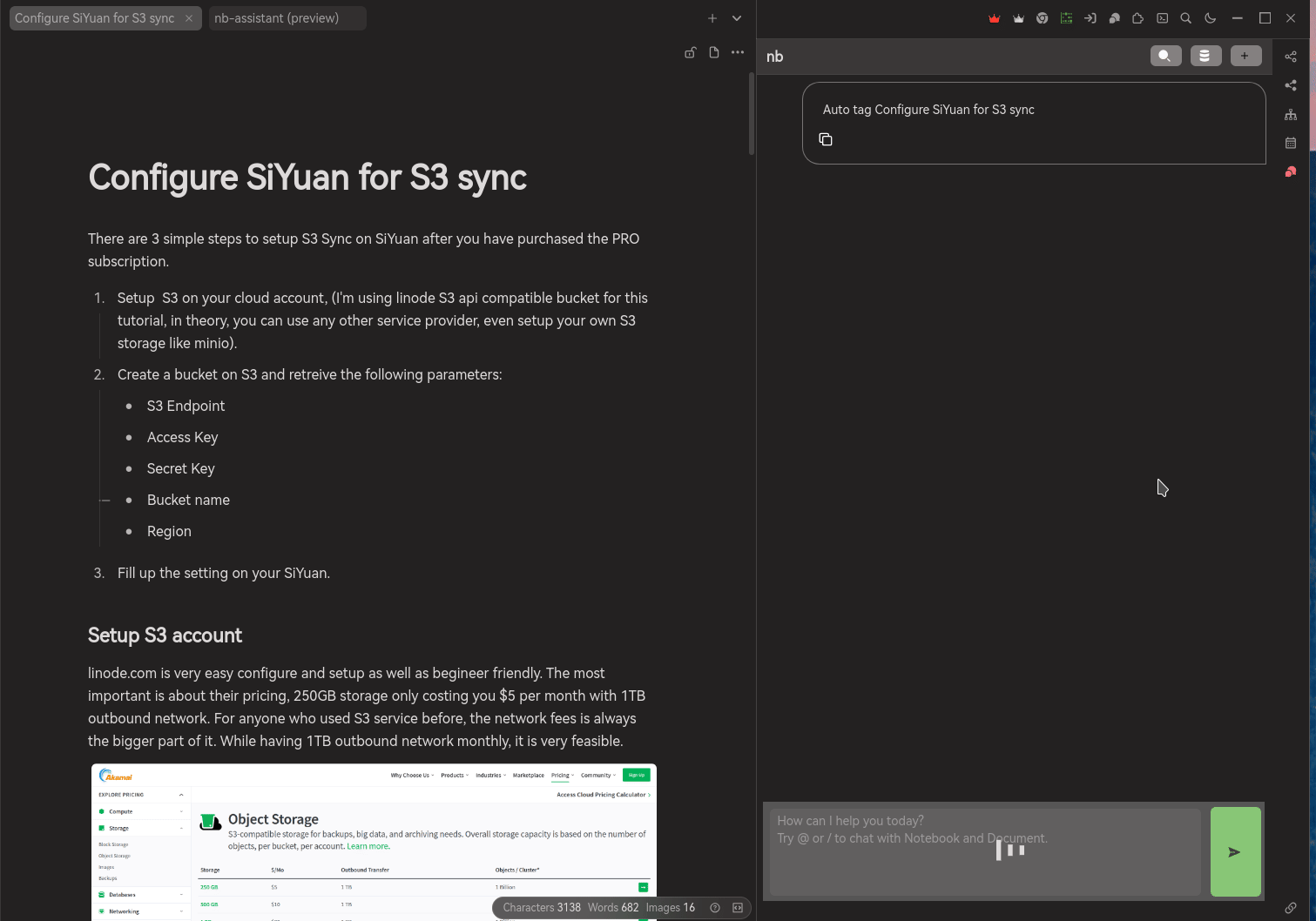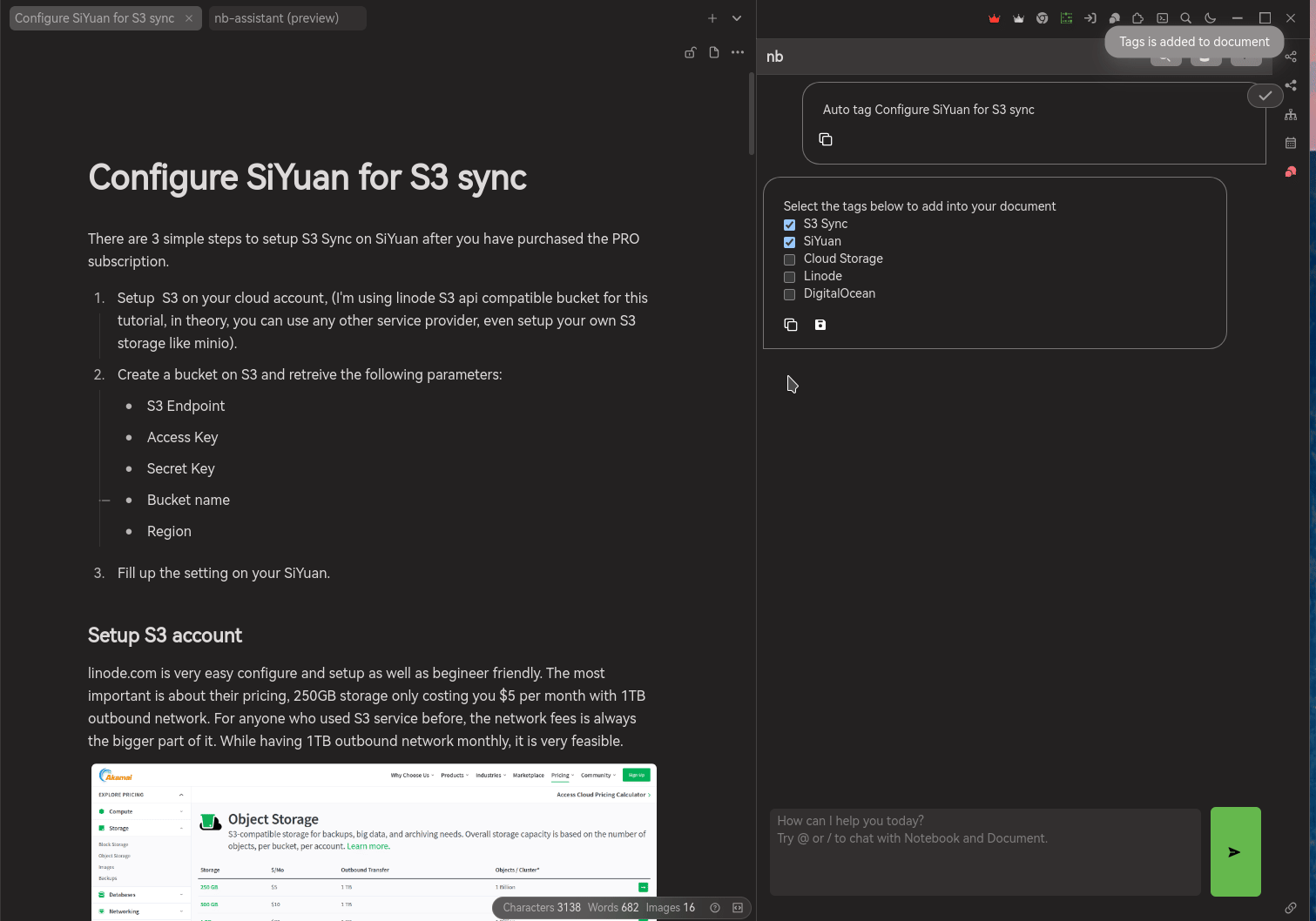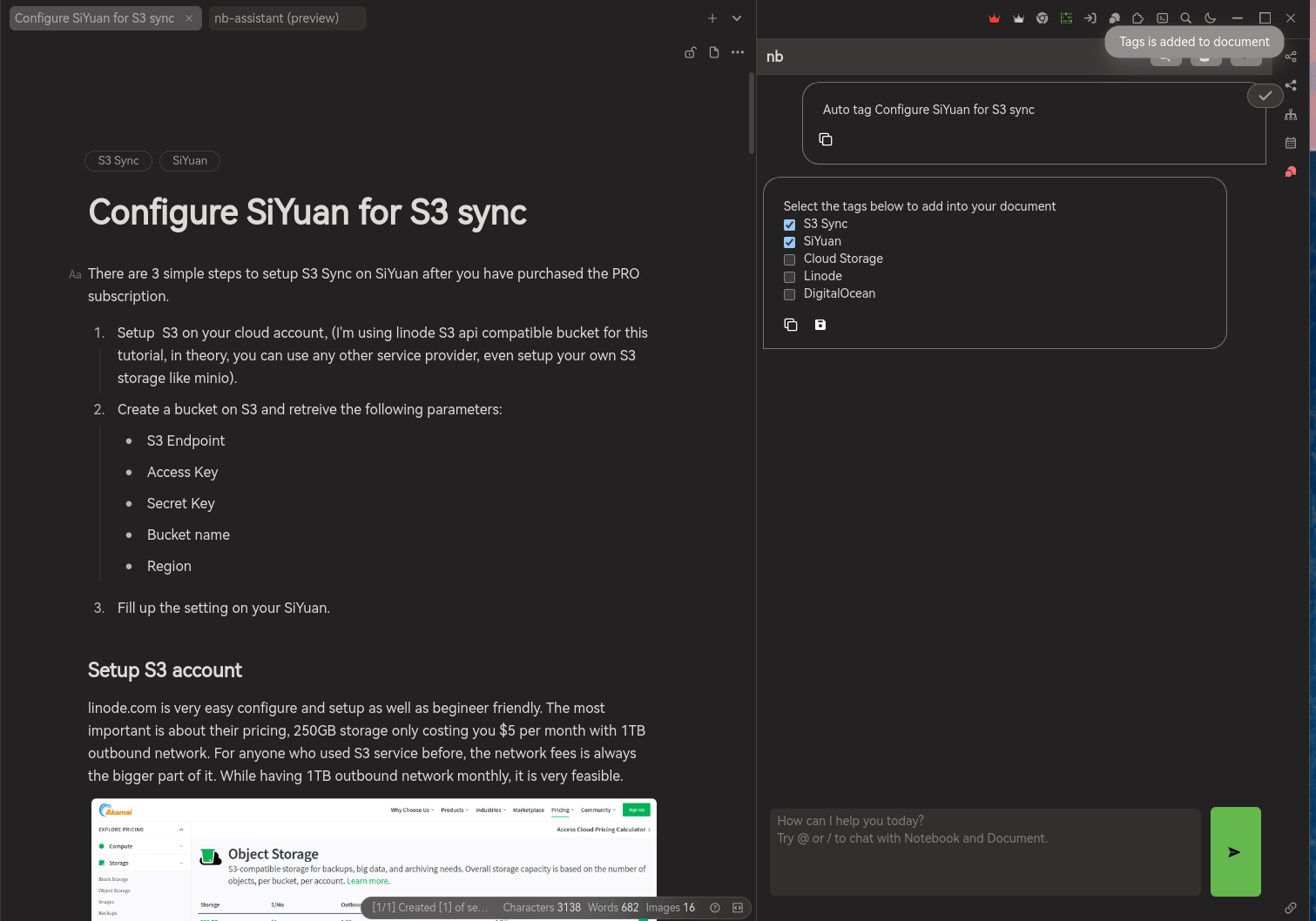
Auto tag the document within the notebook is possible in future development. However, the token usage will be crazy. I'm not implementing it due to cost issue. In the future, the token cost of AI service might be lower or there are a better solution available.
Search across my notebook
While the current full text search on SiYuan is working great, I may forget about the keyword for searching in my documents. Since Notebook Assistant also building for RAG use case, there will be embedding created locally (within your machine and within SiYuan), I'm making use of this embedding blocks for similarity search.
-
Go to the :database: icon page.
-
Select the notebook that you want to create embeddings.
Please ensure you are not create embedding using any notebook that consists of sensitive data, such as credit card info, your national ID, etc. Although the embedding process is done locally, data stored locally. When you using "chat with notebook" feature, it may be retrieved by the RAG process and being send over to AI service for operation. We do not know how the AI service provider is using the data you are sending over, whether there is any privacy issue there.
Therefore, ALWAYS SKIP THE NOTEBOOK WITH SENSITIVE INFORMATION.
-
Confirm the selected notebook and start creating embeddings. Depending on your machine performance and the data you have inside the notebook, it will take 1 - 60 minutes or more to complete the embedding process. During this process, do not close SiYuan or exit Notebook Assistant until it is completed. Sharing from my experience, it tooks about 15 minutes to process 3000 blocks of embeddings (55 documents, average 4500 words each document) locally.
-
Once the embedding process is done, you will be able to see the notebook name display in green tag.
Technically, it is rely on transformer.js and onnx runtime to create the embedding within SiYuan. If you like to know more, visit this page, https://xenova.github.io/transformers.js.
Chat with my content
Since your notebook content has a embeddings copies, you can using it for a RAG use case. A brief explaination provided below (generated by AI) 🤪
[AI] RAG, or Retrieval-Augmented Generation, is a technique used in the field of natural language processing (NLP) to improve the quality and accuracy of text generation models. It combines traditional language models with a retrieval mechanism that allows the model to access and incorporate external knowledge sources during the generation process. Here's a breakdown of how RAG works and its benefits:
Retrieval Mechanism: The key component of RAG is its ability to "retrieve" relevant information from a large corpus of data (like a database, document collection, or the internet) in real-time while generating text. This is different from traditional language models that rely solely on the information they have been trained on.
Augmented Generation: Once the relevant information is retrieved, it is "augmented" or combined with the text generation process. This means the model can use this external data to make more informed decisions about what to generate next, leading to more accurate and contextually relevant outputs.
Benefits:
- Improved Accuracy: By having access to up-to-date and specific information, RAG can generate more accurate and reliable responses compared to models that only rely on their internal knowledge.
- Contextual Relevance: RAG can tailor its responses to the specific context of the query, making the generated text more relevant and useful.
- Flexibility: Since the retrieval component can be updated with new data, RAG models can adapt to new information without needing to be retrained from scratch.
In summary, RAG is a powerful approach in NLP that enhances text generation by allowing models to dynamically retrieve and utilize external knowledge, leading to more accurate, relevant, and flexible text outputs.
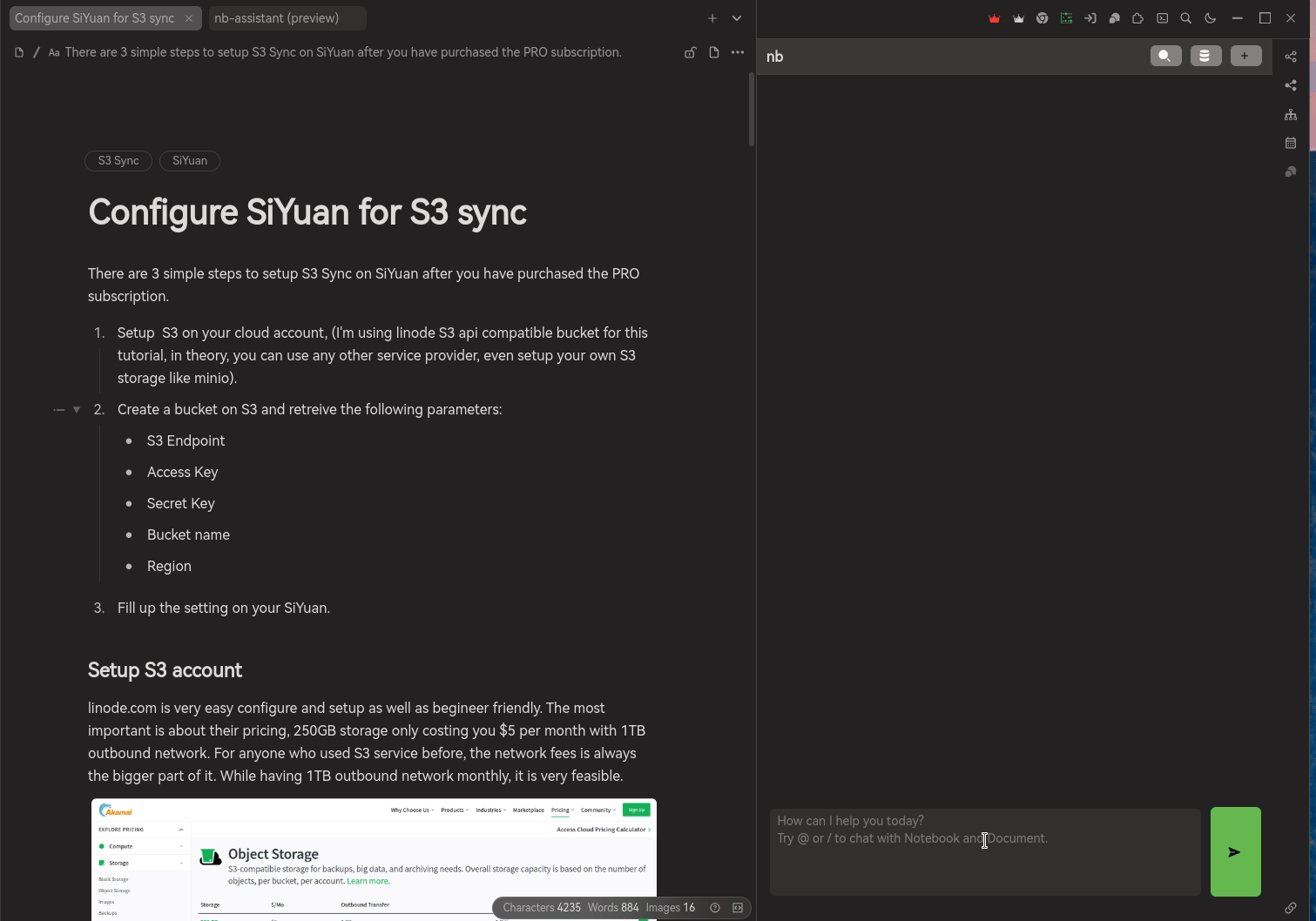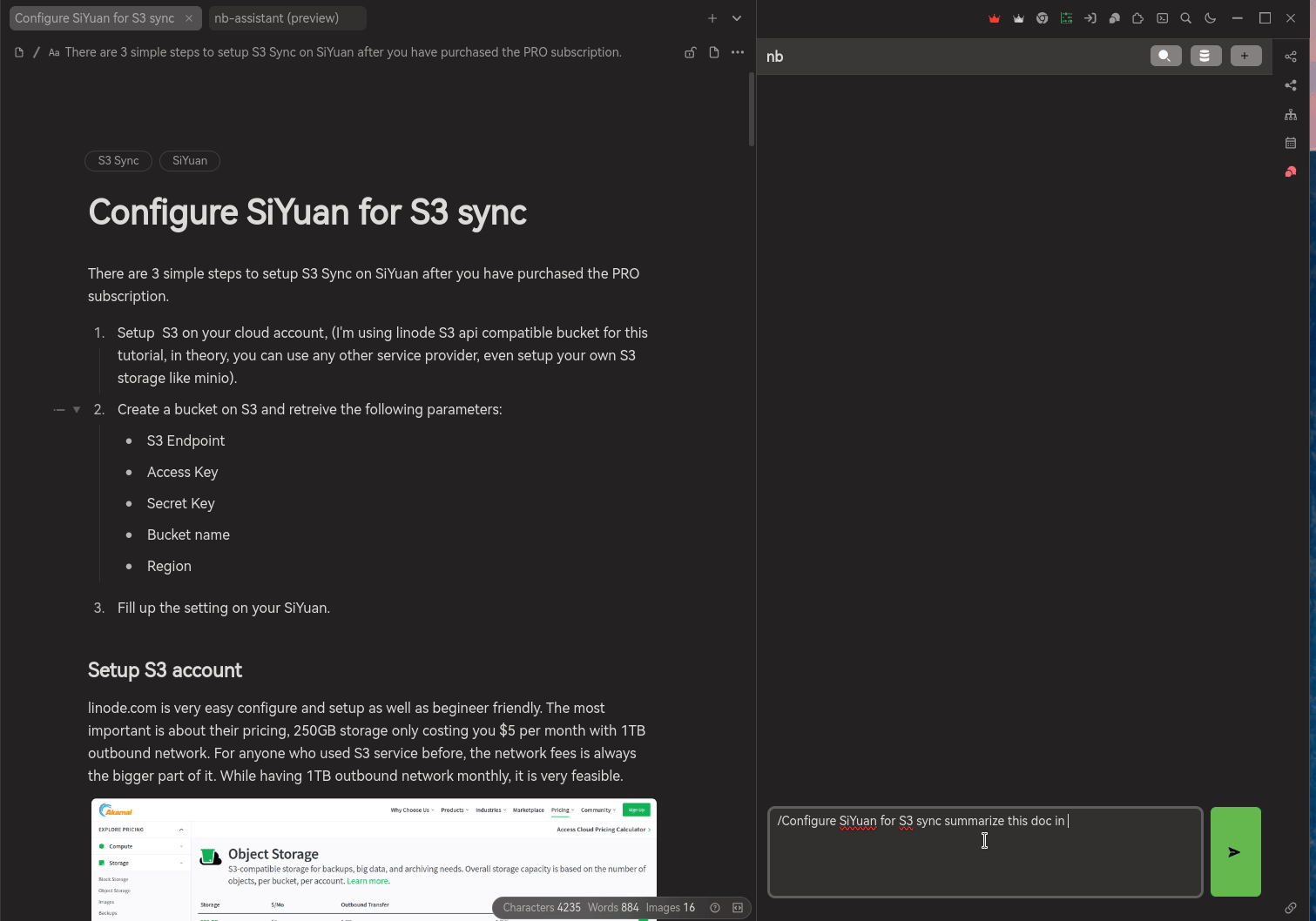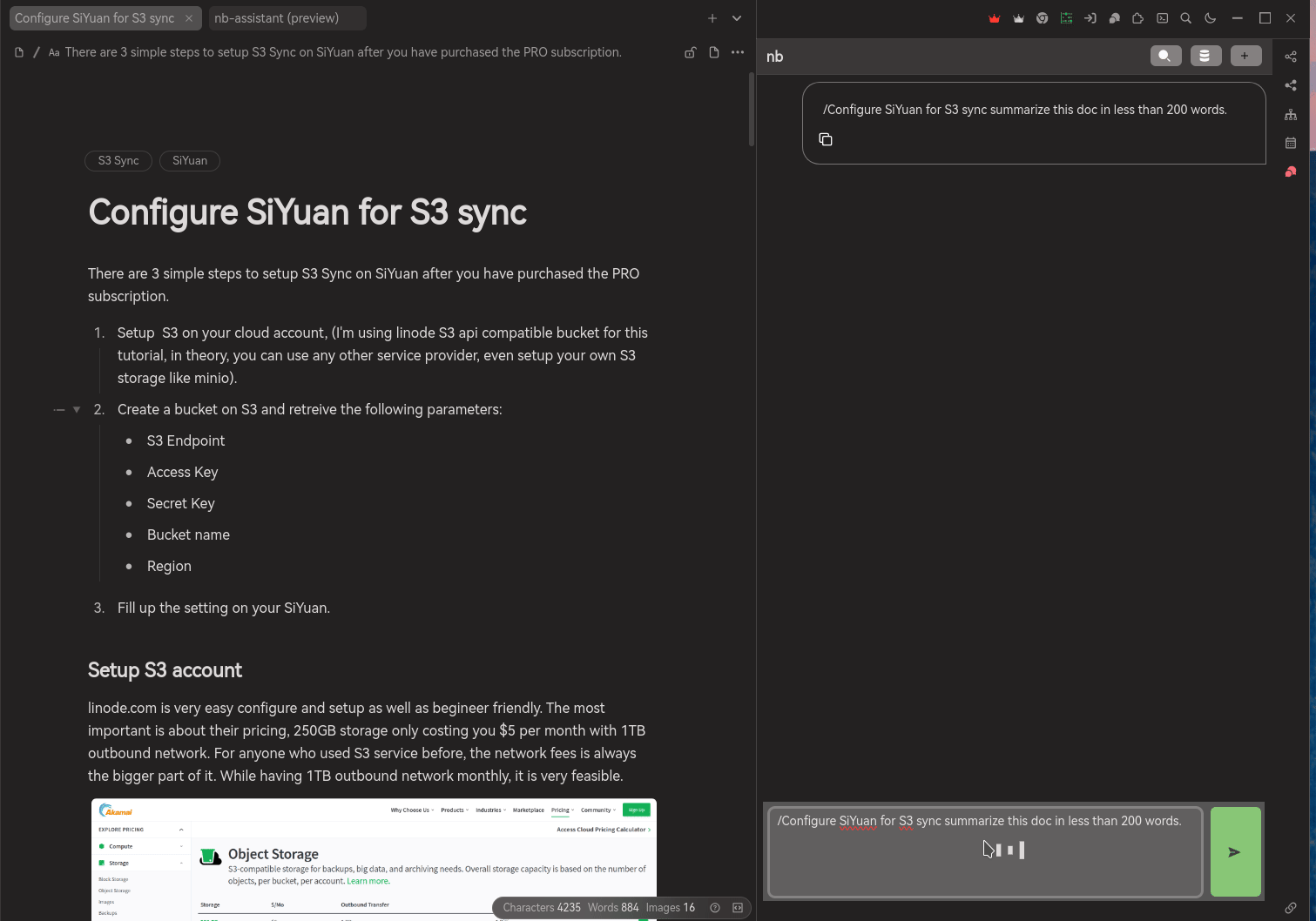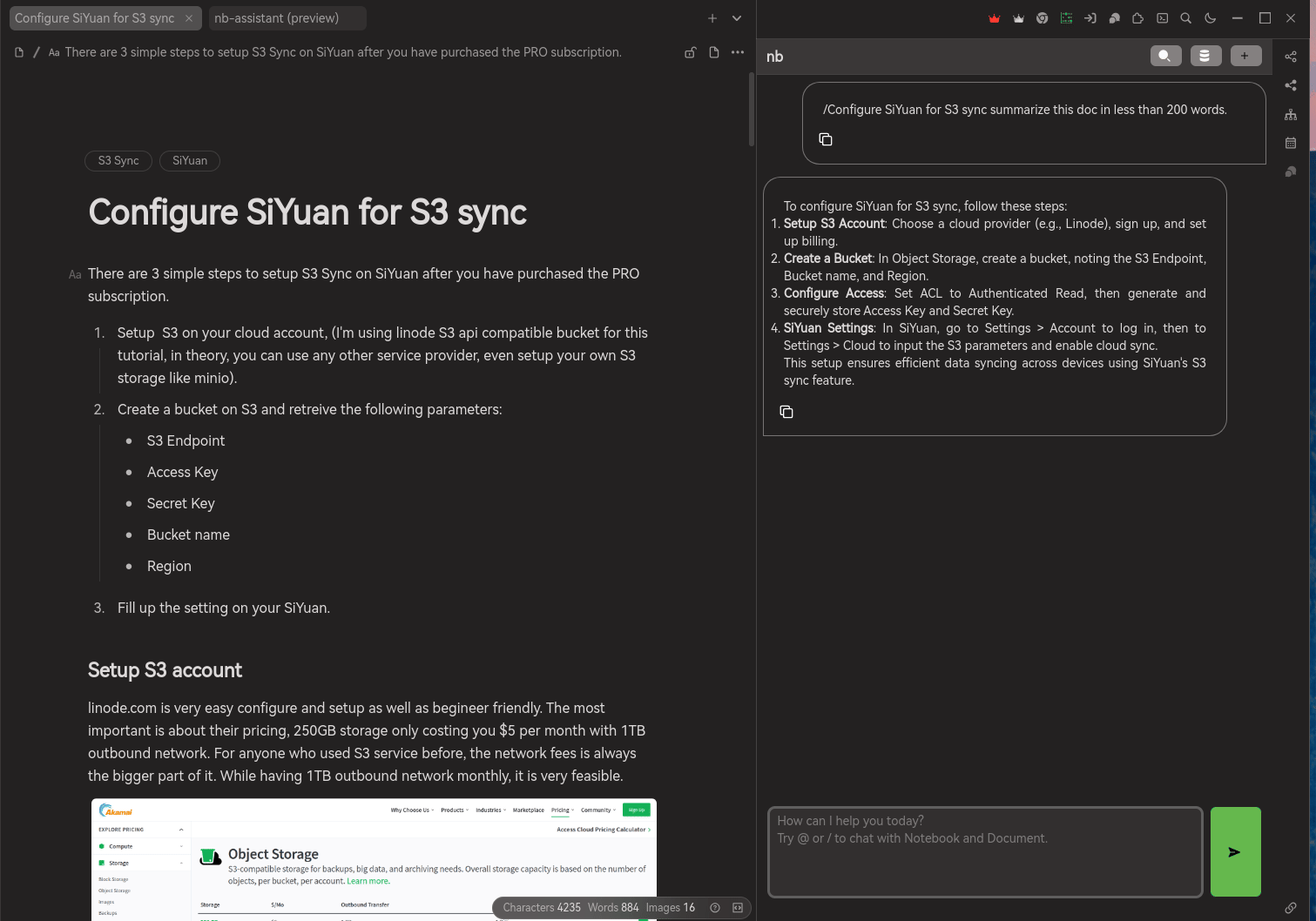
There are two ways to chat with your documents:
-
by triggering
@, there will be a pop up for list of notebooks that have created embeddings locally. Using this option, Notebook Assistant will be retrieve contents from the selected notebook based on your query.
Then, passing it to AI service provider to create a response to answer you. -
by triggering
/, this option do not use your embedding but using your document directly. The document normally have a title / header already, after triggering/, there will be list of documents across all the notebook up for your selection. Once you selected the document, together with your query will be send to AI service provider to create a response to answer you.Similar to create embedding service, DO NOT USE ANY DOCUMENT CONTAINS SENSITIVE DATA. You got to take your own risk while supplying such sensitive data over to those AI service provider.
While the document contents might be very long or your query is not clear towards it, there is a techniques being use to improve this operation.
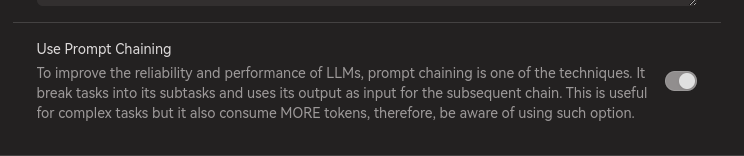
Under Notebook Assistant Settings, enable Prompt Chaining option. This option will do the following:
- Rephrased your chat query
- Create a smaller set of summary based on the supply document
- Answer your query based on the rephrased chat query and smaller set of summary.
While there are 3 simple steps, the token usage is also increased, roughly 2x times or 2.5x times of the original token usage. Therefore, be aware when using prompt chaining, everything come with a cost. ☺️
Limitations
There are one limitations and some bugs being discovered after 0.1.3 is released.
Create embeddings locally has some limitations:
-
Since we are using an quantized model, the embeddings create may not be perfect and some context may have missed during the process. The consequent is, notebook with varies of content, its search results also not very accurate.
-
Transformer.js needs to cache its model in the application, currently, there is no good way to cache it yet. But, but, but, it's about 30 mb of the cache files, so it still not too bad. It may take a bit of your network bandwidth and waiting time on the start up time when using Notebook Assistant.
If you really cannot deal with it, you can visit here (https://github.com/jaar23/nb-assistant#limitation-for-013) for an temporary solution, it is currently available for Linux user / possibly Mac users too, but not Windows user.
I'm using it personally, so there are also bugs I discovered myself and it is log under my github repo's issues. Not to mention, although Notebook Assistant supported on mobile platform, chat with notebook and chat with document is not able to working correctly.
Finally...
I wish you enjoy using this plugin and it at least helps you a little bit. Thank you...
Welcome to here!
Here we can learn from each other how to use SiYuan, give feedback and suggestions, and build SiYuan together.
Signup About